K/V Asymmetry with AdamW vs Muon
Note: If you see anything wrong or have feedback, please don't hesitate email me - elkhouriela at gmail dot com. Or use this link, but seriously, does anyone like mailto:s? I feel like they're usually just inconveniences and make me LESS likely to email people.
This post is not done; I've put it up so I can share it with someone else, but rest assured that it will be updated; it's just that I ran out of compute very quickly when trying to test my hypotheses. I am planning to post the source code with reproduction steps once I finish. Nothing I've done here is particularly enlightening, but this is the first time I've really gone this deep in my short month of trying to brute force LLM intuition, so I feel as if I must celebrate in some way! I am proud of myself in the same way you are proud of your son for winning his first grade soccer game. My mom bought me donuts when I lost my own first grade soccer games, so I can only imagine what the winners got! tl;dr Just want to log some observations for now. Sorry, blog, I said I'd respect you...
Recent widespread interested in KV quantization increased due to the virality Google's TurboQuant enjoyed this March. Multiple independent sources came to the conclusion that the QJL compression method employed in the original paper actually caused quality loss, and re-implementations eventually converged to what is basically HIGGS. (TheTom's repo seems pretty active with some explanatory papers and many more links if you're curious about that)
I caught up with this a few days ago-- April 10 or so-- and experimented a bit with quantization of smaller models locally. To be honest, this did not capture my attention as much as the more handwave-y theorizing about K/V cache asymmetry that appeared as corollary of its re-observation in the context of TurboQuant. I am, unfortunately, quite weak to entertaining and building on handwave-y theorizing, so I set out on a (very brief) journey of K/V enlightenment.
The Landscape :tm:
I made sure to specifically mention re-observation above because we have known about differences between the K and the V for a long time now. In 2024, KIVI (Liu et al.) found that the key cache could be quantized per-channel, but the value cache should be quantized per-token. For obvious reasons, most papers making asymmetry observations are about quantization. {I'll put more here in the final version, since I want to curate what is relevant.}
Yesterday, I saw a Twitter post from Ramp Labs discussing how they decided to handle memory sharing for their multi-agent RLM system via K/V compaction. They mentioned Fast KV Compaction via Attention Matching (Zweiger et al.) from early February-- for posterity, February 2026-- which proposes a compaction method involving
- Finding the individual most attended-to vectors present in any block of the
Kcache (not per block, but the most attended to over all the blocks) and assembling those keys into a compacted - Based on that , fitting a parameter and solving for via least squares
Honestly, there is no way I can explain this better than the paper itself, so if you are curious about that, read it! The general idea is to select actual vectors from to create , then solve for so that the attention using instead of and instead of is similar to the attention with the original .
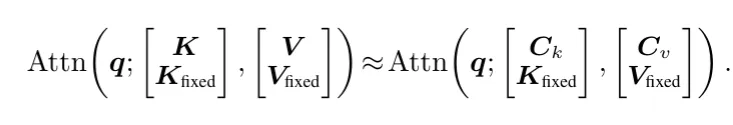
I thought this was pretty cool, and decided to test their code with some models I could run on my local machine. After seeing some cool stuff with a small AdamW model, I decided to get a little esoteric and fire up a Muon one based on a repo my friend sent to me. Though this could easily be due to a disparity in model quality, I was kind of intrigued and decided to do some testing on my own based on the K/V asymmetry stuff I read earlier; I thought there could be something relevant in Muon's consideration of the matrix as one whole thing. I don't really know that much about Muon, so this was more "guy accidentally makes new drug in his sink" than some Walter White orchestrated wizardry.
Experimentation
I think that Muon-trained models have different concentrations in their K/V caches. Specifically, I suspect that the activations are less channel-concentrated than that in AdamW. This is probably due to Muon being geometry-aware, but fuck if I know, man.
I'm not done with the experiment, so I won't go into too much detail, as my methods are likely subject to change. Very much looking forward to finishing up and being able to yap for a while about my choices tho!
The general idea behind my runs was to train two models on the same architecture-- a slightly modded NanoGPT, without the cheeky GPT speedrun techniques-- and same dataset, but use AdamW for one and Muon for the other. Eventually, it would be nice to make sure this still holds up on a Proper Model, but it's not a major priority for me right now.
I think the architecture I eventually settled on is a pretty decent approximation of "this but with Muon instead of AdamW." Though the goal was to measure the differences ceteris paribus, initial tests quickly made me realize that just slapping Muon onto something I'd just gutted and re-constructed to work well with AdamW was significantly disadvantaging it; I made the mistake of sending a model without proper Muon setup out to train overnight, and depleted half of my free Modal credits for the month. Not very yay.
After that, I was left with a slightly-undertuned 125M Muon model (I'll omit "model" from hereon in) and its reasonable-but-still-undertrained AdamW counterpart. Muon ended its 3 hours of training on FineWeb-Edu 10B with a final loss of 3.241, while AdamW saw a lower 3.070 in about 2h5m. To me, this immediately raises red flags, so I know it must be rerun.
Still, I wanted to check some of the metrics I'd identified as being decent signals for K/V cache asymmetry from previous literature. These were:
- For every , , , layer, stable rank and the cosine between the top single update direction and top weight direction (to see if we are expanding in different ways or keeping to the same general pattern)
- The activation stats of KV tensors as they emerge from our attention block; similar KVQuant and KIVI papers, I checked magnitude per channel (pooling batch*token) and then magnitude per token (pooling over heads); used this to get "spikiness" or
max / mean, 99th percentile value over median, concentration in the top 1%, and some other kind of useless values. - Loss with KIVI-style quantization
Out of the above, I thought that the spikiness per channel over the spikiness per token of the K and V caches was a nice metric to focus on. Though I will not claim that any of this is concrete due to the undertraining/improperly-tuned Muon issues, in my smaller-than-125M comparisons and my 125M run I did see that Muon exhibited different traits than AdamW.
- AdamW had
1.236spikiness and2.072spikiness - Muon had
1.157spikiness and1.704spikiness
As previous literature has already found, Muon's weights also exhibited a significantly more isotropic distribution. Yes, I learned that word yesterday. This is not based on spikiness but on stable rank within the weight matrices (on the 1.4B models I link below, Muon's stable rank was significantly higher than AdamW's) and covariance within the KV activation tensors.
I randomly found an AdamW/Muon pair trained by someone else last year, and think it may be cool to continue with, though some of the point of this project was becoming more familiar with model training. Will perhaps run on that soon, since it fits on my local PC.